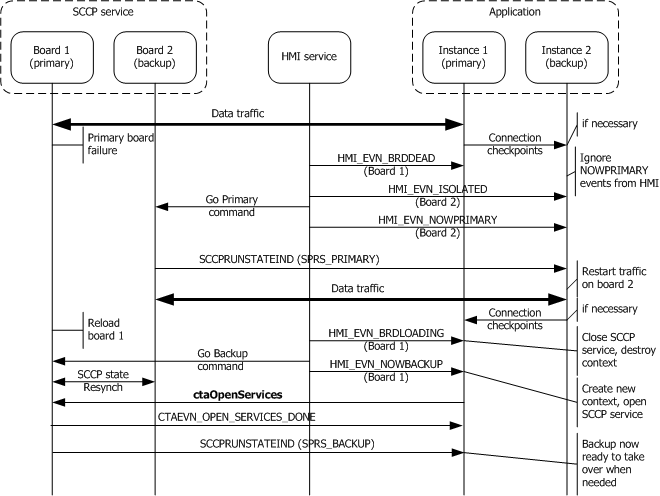
A switchover can also be caused by a board failure (hardware or software). Switchover processing by the backup application instance transitioning to the primary state is similar to a planned switchover.
However, in a failure case, the failed board must be reloaded and placed into the backup state. The application must close the SCCP service and destroy the context associated with the failed board. Once the failed board is reloaded, the application (instance) must create a new context and re-open the SCCP service on the reloaded board.
When the board is reloaded and placed into the backup state by the system manager, the SCCP layers automatically re-synchronize their states so that the newly reloaded backup is again ready to take over in case of a failure of the primary. No application action is necessary to trigger this re-synchronization.